03 Mar 2015, Posté par adminviedoc dans A la une, Outils
Selon une étude récente du Département américain à l’Agriculture (USDA) la pizza serait le met préféré des étatsuniens qui seraient 13% à en consommer tous les jours.
RSS Sourcing, l’outil de veille développé par Viedoc, présente des analogies avec la pizza, ce qui en fait la solution préférée des entreprises en quête d’un outil offrant un excellent rapport qualité/prix.
Le succès des pizzas, qui est un phénomène mondial, tient principalement à ce que la pizza est :
rapido !
pratique
économique
conviviale
bien garnie
à la carte
Commandez la vôtre au 01 30 43 45 27
Le Cappucino est offert pour toute commande passée avant 12h !
Depuis le 1er mars 2015, Viedoc dispose d’un bureau à Montréal, au Canada (Québec).
Notre nouvelle chargée d’affaires locale, Justine Marchand aura en charge le développement commercial de nos outils de veille sur le continent américain.
Viedoc, qui réalise d’ores et déjà 30% de son chiffre d’affaire à l’étranger, poursuit ainsi sa logique d’internationalisation de son activité en se positionnant sur ce marché prometteur.
On constate en effet que les entreprises nord américaines sont familiarisées avec les outils dits de « business intelligence », souvent basés sur l’analyse des big data, alors que pour le monitoring, ce sont plutôt les outils gratuits qui ont le vent en poupe. Mais ce marché semble s’ouvrir à présent aux solutions professionnelles de veille en mode SaaS Européennes, et notamment Françaises. Les outils de veille « made in France » ont en effet tout pour plaire !
Pour une démonstration de notre outil de veille, n’hésitez donc pas à contacter Justine Marchand.
25 Fév 2015, Posté par D. Bocquelet dans A la une, Outils
Ils sont même là pour longtemps encore…
On le sait, les flux RSS sont encore le moyen le plus rapide et le plus efficace pour les éditeurs de distribuer leur contenu en masse, et du côté des consommateurs de réceptionner et de lire ces contenus « à distance » et de manière centralisée. Lancé en 1999, le RSS (Real Simple Syndication) a connu une diffusion d’usage considérable dans la dernière décennie. Cependant avec l’arrivée en puissance des médias sociaux et l’essor de l’email marketing, les flux RSS ont commencé à péricliter. Les Autorités du web (le W3C) ont elles-mêmes approuvé le passage à des solutions de plus récentes, plus intuitives et plus rapides comme Twitter et d’autres formes de médias sociaux « instantanés ».
Toutefois beaucoup de sites d’actualités dépendent encore fortement du RSS – y compris les sites et blogs d’autorité sur les niches populaires, les sites professionnels et étatiques ou gouvernementaux, ceux d’agences, autorités diverses associations, fédérations et autres organismes. Les plus gros utilisateurs/diffuseurs se servent d’un logiciel open-source personnalisé d’analyse de leur diffusion RSS installés sur leurs propres serveurs pour surveiller étroitement les RSS de leurs concurrents afin d’obtenir une longueur d’avance et d’établir une stratégie de diffusion consciente et efficace.
Alors la meilleure manière de déterminer les chances de survie du RSS peuvent êtres de comparer Twitter avec RSS.
Twitter: C’est un total cumulé de 20-30 messages par minute, un twit toutes les deux secondes vus sur des comptes « moyens ». Mais pour en tirer le contenu il faudrait suivre activement les contenus un par un. Utiliser une logiciel pour ça semble compliqué, il faudrait en effet que ce dernier suivre et analyse les contenus remontent le cas échéant des informations sur vos propres requêtes, et vous envoie des alertes ou permettent de capitaliser ces informations à lire plus tard. Mais si une personne « spamme » sur twitter ou se lance dans une conversation via twitter ? le logiciel aura du mal à décerner la part du vrai ou du faux, et pourra envoyer le cas échéant du bruit.
Face à lui, le RSS fait figure de chevalier en armures rutilante…
La plupart des blogs disposent de leur flux RSS. Mais certains en revanche n’aiment pas trop cet usage non contrôlé de leurs informations. Ils préfèrent donc se reposer uniquement sur l’emailing, les newsletters, et le marketing sur les médias sociaux.
Un agrégateur RSS moyen va automatiquement télécharger les informations et les présenter de manière organisée et soignée. Il est alors possible de les lire hors ligne, sur tablette, smartphone, sans même avoir besoin d’une connexion Internet active.
Chaque article ne sera téléchargé qu’une seule fois. Pas de redites donc, pas de « retweet ». Et donc les articles sont naturellement « capitalisés » ce faisant. Ils se présentent donc dans un espace à vous, prêts à être lus, et n’imposent donc pas de suivre un fil twitter sans interruption ou être noyé sous les alertes.
Actualités et flux RSS vont ensemble comme pain et beurre. Ils permettent notamment de sélectionner les informations les plus pertinentes d’un site internet aux nombreuses thématiques et donc de cibler ses lectures, contrairement aux twits qui sont par nature désordonnés. Les procédés d’alimentation sont simple: Un simple lien à ajouter au lecteur. On peut aussi les lire depuis un agrégateur de blog comme wordpress, voire alimenter une page d’actualité avec des flux choisis !
Twitter reste cependant le meilleur moyen de voir les dernières nouvelles, mais aucun service ne réunira des articles spécifiques sur des sujets confidentiels ou précis à partir d’un flux Twitter particulier et ne les stockera dans le même temps pour relecture, ou tout au moins un outil unique. Et il faudra déterminer lequel des ces twits est le plus légitime par rapport à une information potentiellement recyclée artificiellement (IA)… Au final, sans que les utilisateurs s’en rendent vraiment compte, la technologie RSS reste sous la surface un peu comme un protocole TCP-IP, alimentant la communication inter-sites et les interactions de l’information. La plupart des réseaux sociaux fournissent ou consomment du RSS, la plupart des blogs en émettent, des Mash-ups utilisent souvent des flux pour combiner les données, sans parler des outils de veille. Google notamment s’en sert pour alimenter ses moteurs d’alimentation et faire remonter des recherches produits. Des logiciels d’analyse calculent leur utilisation pour déterminer la diffusion des actualités. C’est un quelque sorte devenu un protocole d’échange de données transparent, il travaille silencieusement et efficacement dans l’arrière-plan…
Un secteur que l’on peut qualifier de « difficile », pour plusieurs raisons.
En cause, la nature transverse de certaines activités :
transport maritime > transport
industrie pétrolière > énergie
croisière > Voyage/tourisme…
En exemple, la « cohérence » d’un domaine comme le packaging. Le domaine maritime est en effet une juxtaposition d’industries avec un même milieu naturel, la mer. Les sources d’informations de ce fait sont très dispersée lorsque l’on rentre dans le vif du sujet.
La veille maritime: Une sémantique historiquement confuse:
« veille maritime » induit en erreur car le terme est apparenté à l’ancien « quart » qui s’opère aujourd’hui sous la forme d’appareillages électroniques (radar, GPS, sonar, etc.). Sur le plan du référencement, une simple recherche google permet de voir rapidement les limites de cette requête. Les références sont pauvres, pour ne pas dire indigentes concernant l’intelligence économique (en français) et plus encore la « veille » dans le domaine maritime. En revanche, il existe (en anglais) du contenu sur « maritime business intelligence », même s’il ne s’agit pas du même domaine.
Sur « maritime competitive intelligence », ce sont plutôt les transports en général qui sont considérés. Il faut donc croire que la requête n’est jamais tapée. « maritime intelligence », en revanche possède un sens tout différent, puisqu’il s’agit essentiellement du tracking en temps réel et de l’évaluation des risques dans le domaine du transport maritime (un domaine particulièrement en verve depuis l’explosion de la piraterie sur les routes commerciales le long de l’Afrique subsaharienne). Ce qui renvoie aux sociétés de sécurité et aux consultants en évaluation des risques maritimes.
Les veilles maritimes: Des facteurs d’innovations prometteurs:
Paradoxalement, qu’ils s’agisse de nouveaux matériaux, nouvelles formes optimisées, énergies propres, ressources halieutiques, exploitation des minéraux de grand fond, industrie pétrolière, nouveaux types de propulsion, les innovations abondent. Le domaine maritime n’est en aucun cas figé et coupé de l’innovation.
Toutefois pour une industrie mature, ses ressorts d’innovation sont fortement contraints par des tensions économiques déjà anciennes (le tarif de transport de marchandises, le coût du brut, etc.). On peut en dire autant pour les géants de la croisière qui épient leurs formules au centime près… On est donc d’avantage passé dans le domaine de l’hyper optimisation plus que sur des nouveautés révolutionnaires et fracassantes.
Un bon exemple : Le transport à la voile, dont le retour (modernisé) était déjà prophétisé dans les années soixante-dix suite aux crash pétroliers, n’a jamais pu s’imposer, notamment du simple fait de la taille et de l’encombrement des voiles sur un porte-conteneurs !
A ce titre j’ai tenté d’effectuer la lumière sur les méthodes de la veille maritime, conduisant au final à une étude des enjeux et des méthodologies à découvrir:
L’arrivée récente de The GRID a provoqué du remous dans le landernau des webdesigners. Une profession il est vrai de peu de poids sur le plan médiatique, quoiqu’elle puisse présenter concrètement son travail contrairement aux référenceurs. Or, the Grid n’est pas le surnom d’un ensemble de réglementations contraignantes venant contingenter ladite profession mais une intelligence artificielle censée créer des sites internet « at random », apparemment de manière autonome. Une vraie révolution ou un beau ballon marketing ?
C’est ce que nous allons essayer de décoder.
D’abord ce n’est pas un projet encore 100% mature, puisqu’il est actuellement en phase de financement, précédé d’un projet kickstarter (maintenant fondé en 2013), NoFlo, une plateforme ergonomique pour développeurs. Ce projet à l’étude depuis 3 ans et demi réunit une équipe de 4 membres fondateurs, Dan Tocchini, (CEO et Co-Fondateur de la société), l’Ex-directeur produits de Google AdSense Brian Axe, Le lead designer Leigh Taylor et le directeur technique Henri Bergius, réunis à San Francisco en 2010.
L’équipe espère lever sur son propre site 70 000 dollars pour finaliser le développement et lancer le produit commercialement en mai prochain. Les fondateurs (plus de 200 000) se verront gratifier alors de bénéficier d’un avoir leur permettant de disposer de leur propre site à 8 à 25 dollars au lieu de 95 par mois, prix public.
D’après Dan Tocchini, « Nous avons passé les quelques dernières années à créer une forme d’intelligence artificielle qui fonctionne comme votre propre graphiste personnel, capable de penser votre marque et de la présenter de la meilleure façon possible. Le design s’adapte à votre contenu, et non l’inverse. » Il est dit que la solution se passe de template et peut gérer textes, images, vidéos, URL… en temps réel, pour créer le meilleur assemblage possible. Au final, chaque site est censé être unique et taillé sur mesure. Les cibles: WordPress, WIX, Drag&Drop…
Un bon pedigree pour un produit qui se veut à première vue (encore!) une plateforme centralisée de création de sites internet. Le principe est simple et on peut trouver ce type de plate-forme partout sur le web, dès lors que l’on google « site gratuit ». Le marché est devenu mature avec une short-list de plate-formes qui se sont rachetées les unes les autres et des modèles de financement maintenant bien huilés. Comment innover encore sur ce créneau saturé ?
The GRID compte donc créer la surprise en appelant simplement la dernière étape logique après lesdites plate-formes qui étaient déjà hautement automatisées. Le principe en était que les utilisateurs conçoivent eux-mêmes leurs sites à partir de systèmes de templates et d’un éditeur Wysiwyg. En principe personne n’intervenait dans le processus de création et le résultat final était une combinaison de la qualité de l’éditeur en génération de code (propre, intelligent et léger… ou non!), et des choix personnels de l’utilisateur, pas forcément formé au webdesign ni au marketing.
L’étape suivante était donc de supprimer l’utilisateur de l’équation en laissant faire par une intelligence artificielle toute la phase d’intégration des contenus et leur mise en page. Il ne s’agit pas à en croire The Grid d’un processus 100% autonome, puisque l’utilisateur a quand même quelques choix éditoriaux à faire et garde la maîtrise de son contenu, mais le processus de mise en page et toutes les opérations satellites sont effectuées au dire de l’équipe, en toute autonomie. Le lancement du concept s’est accompagné d’une réflexion sur le métier de webdesigner, au sens plus large, et la reconnaissance de la difficulté croissante de son travail. Une difficulté qui le condamne à long terme -c’est en tout cas le pari fait par The Grid.
Concrètement de nos jours, un(e) vrai(e) webdesigner, c’est à dire un(e) professionnel(le) qui ne soit pas qu’un(e) simple « infographiste », doit pouvoir matérialiser en code interprétable par les navigateurs un design 2d issu de photoshop ou autre application en site internet fonctionnel avec l’apparence requise. Les interactions, qui ne se voient pas dans un design web, sont ensuite définies en fonction des connaissances du webdesigner et des attentes du client et des pratiques de la concurrence en matière d’interactivité. Ce travail peut intégrer un framework existant (comme bootstrap), qui permet d’avancer beaucoup plus vite que de développer tous les éléments à façon, réduisant d’autant la facture. Mais il reste à intégrer des éléments de responsivité et des plugins, API et autres éléments qui peuvent être conflictuels. Et il ne s’agit même pas d’habillage de template et customisation de CMS.
Le choix des couleurs, tonalités et mises en pages des photos par rapport au texte, etc… relèvent de décisions quasi « artistiques » qui font appel au goût et aux pratiques observées ailleurs. Il s’agit de choix en apparence subjectifs et associés naturellement à un être humain, pas à une IA.
La première simple déduction concernant le produit vient du doute qui s’installe quand au fait que ce système peut créer des sites vraiment personnalisés. A voir les screenshots, on n’en est pas forcément convaincu. En effet à la base, il a fallu penser pour mettre au point les « goûts » supposés parfaits de l’IA et le programme derrière les choix de mises en page reflètent les choix personnels des techniciens derrière, notamment Leigh Taylor et Brian Axe. On ne peut pas ne pas suivre les modes en matière de design web et il est certain que si cette AI n’est pas capable de les suivre, les designs seront vite « datés ». Qui plus est il est assez facile aujourd’hui de détecter des sites « made in bootstrap », ou les CMS avec templates populaires. Il y a de fortes chances qu’il en sera de même avec The Grid.
Une IA serait-elle capable d’engendrer des millions de sites totalement différents ? Sur le plan mathématique seulement. Car s’il on considère les tendances marketing, les modes du webdesign et l’ergonomie la plus récente en usage, cela va vite donner à ces produits un goût fort de « déjà vu ». Les clients seront-ils d’accord au final avec le résultat de de l’IA ? Serait il possible dans le cas contraire d’effectuer des modifications ou faudra t’il effectuer un « shuffle » avec le risque que la nouvelle mouture ne soit pas plus convaincante ?
Il est vrai cependant que la simple faculté de générer automatiquement un site internet en changeant quelques paramètres va permettre de faire ce qui prend bien trop longtemps à un webdesigner avec des méthodes classiques. Et en soit c’est déjà considérable car cela donne aux clients de plus fortes probabilités d’êtres satisfaits avec le moindre effort…
Pour rependre les termes officiels, l’IA serait capable de:
– « Collecter » des images et du texte venant d’Internet via un navigateur ou extension mobile pour la mise en page du site.
– Analyser le contenu soumis et créer un site web réactif en seulement trois minutes.
– Automatiser la gestion des couleurs, le découpage la mise en page du texte et son positionnement sur les images. Le logiciel sensible au contenu détecte les contrastes et détermine en conséquence leur position optimale.
– Recadrer automatiquement les images à l’aide de fonction de détection des visages ou objets.
– Construire un site web entièrement depuis un smartphone ou une tablette.
– Publier du contenu directement sur plusieurs sites Web à partir d’une source unique.
– Utiliser un « call to action » adaptatif (fonctionnalité-clé/commerciale) disponible fin du printemps 2015.
Alors, Les webdesigners seront-ils au chômage lorsque d’autres plate-formes auront repris la même formule ?
Il est certain que si elle ne finit pas en flop après un ou deux ans d’exploitation, l’idée reste séduisante… pour les financiers. Elle procède d’une étape logique qui associe les progrès des IA auto-apprenantes et gomme progressivement le maillon humain de l’équation, en allant vers plus d’efficacité supposée. Un code 100% généré pour un projet unique est en effet mille fois plus avantageux qu’une solution « bâtarde » comme un CMS avec template et plugins, trois échelons qui ne se marient pas forcément bien et coûtent cher, et génèrent des kilomètres de code superflus et redondants. C’est aussi plus séduisant sur le plan financier qu’un site 100% unique mais 100% humain, avec le temps de travail qu’il faut bien rémunérer. Avec des conséquences pour la vitesse de chargement, meilleur expérience utilisateur, moins de place prise sur le serveur, et au final, moins d’énergie consommée dans le monde « réel ». Créer un site sur mesure en le codant à 100% à la main prends beaucoup de temps. Une IA pourra le faire presque gratuitement, si ce n’est le travail derrière pour développer l’IA et l’interface utilisateur.
Enfin, cette IA est bien en charge du webdesign et ne gère apparemment pas les aspects Marketing et référencement, avec les conséquences que l’on imagine très vite. Ce projet n’est donc viable que pour la même catégorie de « clients » qui plébiscitent les sites « gratuits » et dédaignent les agences: Commerçants, artisans et TPE-PME, particuliers, qui ne connaissent que l’aspect premier d’un site internet: Son apparence. Les grands sites seront eux toujours sur mesure car feront toujours appel à une intelligence bien humaine tant leur réalisation relèvera de négociations et d’équilibrages complexes, bref un travail d’équipe autour d’un cahier des charges et de la vision d’un client, avec une vraie stratégie d’ensemble qu’aucune IA ne pourra jamais satisfaire.
Quand à la plateforme, les bases profondes de son fonctionnement dépendent de …webdesigners. Si ces derniers disparaissaient il est facile d’imaginer les conséquences d’un web « bas de gamme » entièrement généré par des IA. Une uniformisation totale à terme, faits de sites tous « parfaits » car tous sur-optimisés. Une vision Orwellienne de couloirs interminables constellés de portes identiques sur fond cliniquement blanc. Une image à la « matrix »…
Edit: Le 7 juin 2016, WIX (Israel), plate-forme CMS bien connue, annonce à son tour une Intelligence Artificielle de webdesign. La course est lancée pour les grands opérateurs du web 1&1 MyWebsite, Jimdo, I-Monsite, Weebly…
12 Fév 2015, Posté par B.Galimand dans Etudes, Société
Les 4 et 5 février dernier Viedoc, cabinet spécialisé en veille et intelligence économique, était présent au salon PCD & ADF qui se tenait à Paris, représenté par Bruno Galimand, Michel Vandromme et Wanda Tardy.
S’il existe des outils performants permettant de faire des analyses statistiques sur les volumes de brevets publiés, il n’existe pas aujourd’hui de logiciel capable de remplacer d’analyse humaine lorsque l’on souhaite utiliser les brevets à des fins de transferts de technologie, d’innovation ou d’analyse concurrentielle.
Cet évènement majeur est devenu au fil des ans un rendez-vous incontournable du packaging où les plus grandes marques de la cosmétique et des parfums rencontrent leurs fournisseurs d’emballage.
Sur invitation de Oriex Communication, la société organisatrice de cet évènement, Viedoc est intervenu lors de l’une des nombreuses conférences proposées lors de ce salon.
Lors de cette intervention, Wanda a exposé à l’auditoire l’une des méthodologies mises en œuvre par Viedoc lors d’une veille brevets, en détaillant à la fois la partie recherche et collecte des brevets pertinents et la partie analyse des données et représentation des résultats.
Les logiciels de veille ne sont pas si nombreux que cela, mais il en existe tout de même un certain nombre sur le marché. Certains sont gratuits et mono-tâches, d’autres très onéreux et complexes à utiliser.
Il y a donc de la place entre ces deux extrêmes pour un outil abordable et complet offrant non seulement une surveillance centralisée des sources d’information, mais aussi disposant des fonctionnalités essentielles et avancées à l’activité de veille.
Parmi les quelques solutions de veille abordables, RSS Sourcing (alias le Veilleur Virtuel) fait figure de pépite, une référence plébiscitée par tous ceux et celles qui l’ont utilisé.
Sa simplicité d’utilisation et ses fonctionnalités innovantes sont ses points forts, rendant possible son déploiement au sein d’une entreprise ou d’un service, sans avoir besoin de planifier des formations coûteuses. Les paramétrages sont à la portée de tous, et l’outil est évolutif de façon à s’adapter aux besoins de chaque utilisateur.
Par ailleurs, notre créativité n’étant jamais en sommeil, Viedoc bêta-teste actuellement la version 3.0, qui sortira d’ici quelques mois.
Résumé: Patents are a great source of information for many reasons and at Viedoc, we think that companies should be more aware of this. Patents may seem hard to come around at first glance, but with (a lot of) patience, with a good methodology and some training most people can find their way through them. Although searching and going through patents may be very tedious, patents are a valuable source of information, as they will provide you with very useful information on:
• the market in general
• what your competitors are working on
• latest innovations and developments in your field
• technical solutions from other fields
Aerosol & Dispensing Forum is a very unique event which gathers every year in Paris the leading suppliers of aerosol and dispensing systems and the major brands in the cosmetic, perfumery, and hygiene businesses. At ADF 2015, Viedoc Consulting was given the opportunity to present its approach to gathering technical & competitive intelligence from patents.
This complementary document presents a case study focused on dispensing devices and systems patents filed in 2014. It explains how to organize and refine a search using Espacenet, the free patents database form the European Patent Office. It also shows how the data collected can be used to understand what is going on both technical and market grounds.
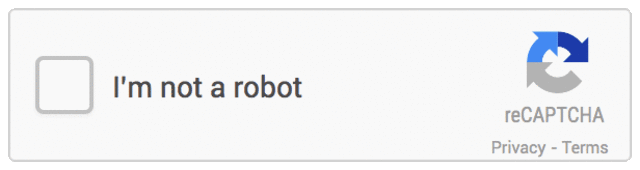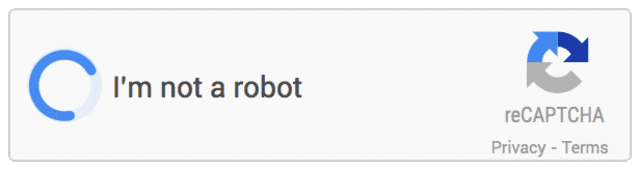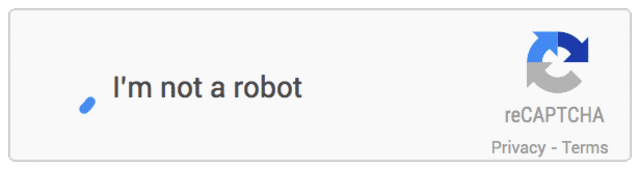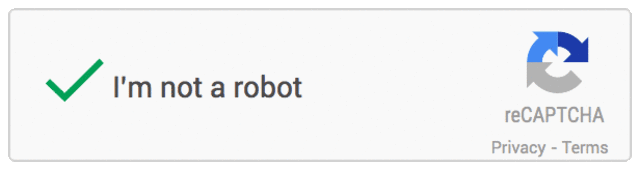
Ou pour préciser un peu plus les termes, « fin annoncée par google. » En effet, les avances en matière de détection du comportement et algorithmes associés permettent au géant de Mountain View de présenter son alternative nommée reCAPTCHA en décembre dernier. Le système sevrait se déployer sur le nombre considérable de sites internet utilisant un formulaire et est particulièrement rafraîchissant dans son fonctionnement.
En effet, plus besoin de s’infliger la corvée de discerner et reporter une suite de chiffres et lettres torturées avant de valider son envoi (En outre sous peine se tromper et perdre son message, en plus de passer pour un robot !). Avec son nouveau système Google ne demande que de cocher une case « je ne suis pas un robot », ni plus ni moins. Ce que fait l’API de Google est en fait de discerner et d’analyser l’interaction avec reCAPTCHA pour valider la nature de l’intervenant. Si par malheur vous passiez encore pour un robot (peut-être moins d’1% des cas selon Google) un système de captcha alternatif serait proposé, apparemment bien plus efficace que le traditionnel jimbo de caractères: Une série de photos, mises en relation. Typiquement une photo de chat qui correspondra avec d’autres chats/chiens/perroquets/plantes/etc. D’apparence inoffensif ce petit quizz est un piège à robot, car l’analogie ne peut se faire sur des critères de formes/nuances automatiques volontairement modifiés pour casser tout exercice logique – au moins du point de vue d’un ensemble d’algorithmes. Parmi les utilisateurs du nouveau système de Google citons Snapchat, WordPress et Humble Bundle.
Quid du traditionnel captcha ? D’après Google il serait maintenant complètement inefficace car « cracké » à 99,8% par les robots actuels.
Un peu d’histoire…
Rappelons un peu les origines du problème: Nous sommes dans les années 1990, et internet est encore dans sa petite enfance. Les intérêts financiers en moins, le spam est un concept encore pionnier dû à de rares hackers. On ne se méfie alors aucunement de laisser bien en clair son adresse mail sur son site internet. Entre temps la bulle internet est passée par là et virtuellement tout le monde se voit doté d’au moins une adresse mail. Une aubaine pour les publicitaires qui commencent à récolter par tout les moyens les mails de prospects potentiels. Très vite, les ex-hackeurs se font rémunérer pour passer d’un travail laborieux, souvent manuel, à une suite d’algorithmes calibrés pour détecter et collecter ces adresses, puis diffuser du contenu à ces mêmes adresses. Des robots, ayant bien des points commun avec les crawlers utilisés pour la recherche internet au sens large.
Puis vers le milieu des années 2000 avec la seconde bulle internet, l’industrie du spam atteint des records. Un internaute peu méfiant se verra arrosé copieusement d’offres « commerciales » manquant singulièrement de finesse, voire embarrassante, et pourra en outre laisser son adresse en s’inscrivant à de multiples services gratuits, sans garantie dans l’utilisation des données. Les fournisseurs d’accès et hosteurs mail unissent leurs efforts et proposent alors d’établir une stratégie de filtrage antispam dont la vigueur va croissante, parfois même zélée, tandis que les spammeurs jouent au chat et à la souris en multipliant les parades, dont des adresses d’envoi changeantes sans cesse, des variantes sans fins dans l’objet, le contenu, etc… De vrais mails « légitimes » pâtissent alors de cette guerre silencieuse au grand dam des utilisateurs de boîtes mail, et même l’utilisation d’un certificat serveur n’est plus forcément une parade.
Entre-temps les formulaires de contact font leur apparition: Ils ont un double avantage. Ils masquent aux robots l’adresse a laquelle les données vont être envoyées (sauf lorsqu’elles sont encore présentes dans le code de la page) et permettent le cas échéant de récolter des données classées sur des prospects potentiels. Les captchas font leur apparition ensuite, car les référenceurs « black hat » on pris l’habitude de développer des robots calibrés pour déposer des « pseudo-contenus » en masse sur tous les sites internet possibles, assortis de liens sur optimisés. Si la chose est connue très tôt sur les blogs ouverts aux commentaires et aux forums, elle nuit également aux sites internet avec formulaires car les données remplies peuvent être de la réclame de même type que le spam classique (« mail »). Et pour y faire face, on déploie différents types de captcha (de « Completely Automated Public Turing test to tell Computers and Humans Apart ») destinés à effectuer ce contrôle avant validation. Le fameux « test de Turing » fut élaboré par le génial mathématicien et pionnier des ordinateurs Alan Turing dans les années 40.
Les captchas sont en général du type visuel, un champ suivi d’un affichage visuel aléatoire présentant une suite de lettres et/ou de chiffres, générés grâce à des images composites qui avec le temps sont brouillés pour empêcher leur lecture par des robots, moins exercés que l’oeil humain à discerner un dessin au sein de formes complexes. Toutefois cette course aux armements avec des robots de pus en plus performants (et aidés par la standardisation des Captchas) conduisit à des déchiffrages parfois même difficile pour des humains. D’où frustration, colère parfois, de se voir refuser une simple prise de contact à cause d’un système de protection. A cette fin un « shuffle » (bouton qui recharge le visuel) ou captcha alternatif (audio par exemple) sont apparus pour éviter ce blocage. Toutefois la courbe d’apprentissage et la vitesse d’exécution (pour de robots testant les solutions jusqu’à épuisement) font que cette guerre est perdue dans tous les cas.
Même avec reCAPTCHA Le problème reste présent
Ne nous racontons pas de contes de fées, le système de Google ne fera que simplifier la procédure de sécurité, mais elle ne stoppera en aucun cas le spam, qu’il provienne ou non d’ailleurs d’un formulaire de contact. Il est bon de rappeler une vérité toute simple, dont se servent abondamment les robots: Chaque nom de domaine pour des raisons pratiques, souvent dans un cadre professionnel, se voit doté d’au moins une ou plusieurs adresses mails, assises sur le nom de domaine ou un nom de domaine proche. L’exemple le plus simple est « contact@monsite.com » ou « info@monsite.com » qui peuvent êtres simplement présumées exister. Un robot qui détectera des noms de personnes pourra de la même manière décocher des mails en reconstituant des adresses de contact fictives: Exemple: Pierre Dupont pourra devenir avec de grandes probabilités de vraisemblance basée sur des cas analogues, p.dupont@monsite.com ou simplement pierre.dupont@monsite.com. Un bémol cependant. Sur un serveur d’ou partent des mail, surtout quand ce dernier est mutualisé (donc peu cher, ce qui convient parfois aux hackers) ont des garde-fous non seulement pour empêcher les envois de mails massifs, mais également les trop nombreuses erreurs de mail (légitimes ou testées). Le ratio varie de 1 à 10% et plus selon la tolérance appliquée. Il y a aussi les mailings sur des bases de données datées (très) qui engendrent également des erreurs. Pour le reste, cela ne gêne aucunement les hackeurs qui utilisent des PC ou serveurs zombies pour leur envois de mails et « grillent » ces derniers.
Pour les systèmes de contact sans collecte (base de données) l’envoi des données à partir e la page du formulaire se fait sur une adresse collectrice, tandis qu’un mail de confirmation de contact est bien souvent envoyée à l’utilisateur du formulaire (cela vaut pour toutes les inscriptions en général). Or, le mail part du site internet (pop) et pour être vu comme « légitime » par les serveurs receveurs (smtp) il doit en principe être identique au nom de domaine. On en revient donc à la forte probabilité d’utiliser une adresse mail basée sur le nom de domaine, que les robots utilisent à plein.
Comment se prémunir du spam:
Dans l’absolu, les captchas ne sont pas infaillibles, on peut faire attention à ne jamais laisser son adresse mail en clair ou se restreindre d’ effectuer des inscriptions pour des services gratuits d’utilité souvent douteuse et prenant cet alibi pour effectuer de la revente d’adresse. On peut aussi utiliser à dessin une adresse pour cette fin, et utiliser une autre adresse pour échanger avec ses contacts. Enfin on peut aussi utiliser une adresse mail, même professionnelle, difficile à deviner, comme pdcont@monsite.com pour « prise de contact » par exemple, voir des adresses ne faisant pas de sens pour des robots (mais qui paraîtront bizarre aux receveurs humains !). Il en est de même pour les adresses personnelles ou l’on peut éventuellement mixer de manière un peu savante noms et prénoms (les prénoms sont connus des robots). Faites preuve de créativité et organisez vous !
Les brevets sont une vraie source d’information au service de l’innovation technologique et de la veille concurrentielle.
Cette année, en tant que partenaire du salon PCD & ADF et sur invitation de ORIEX, société organisatrice de cet évènement incontournable du packaging, Viedoc interviendra mercredi 4 février lors d’une session consacrée aux aérosols et systèmes de propulsion.
» Patents may seem hard to come around at first glance, but with (a lot of) patience, with a good methodology and some training most people can find their way through them. »

































{kind=link}